
How did we rank above human superforecasters using frontier LLMs
and what does that mean for forecasting benchmarks


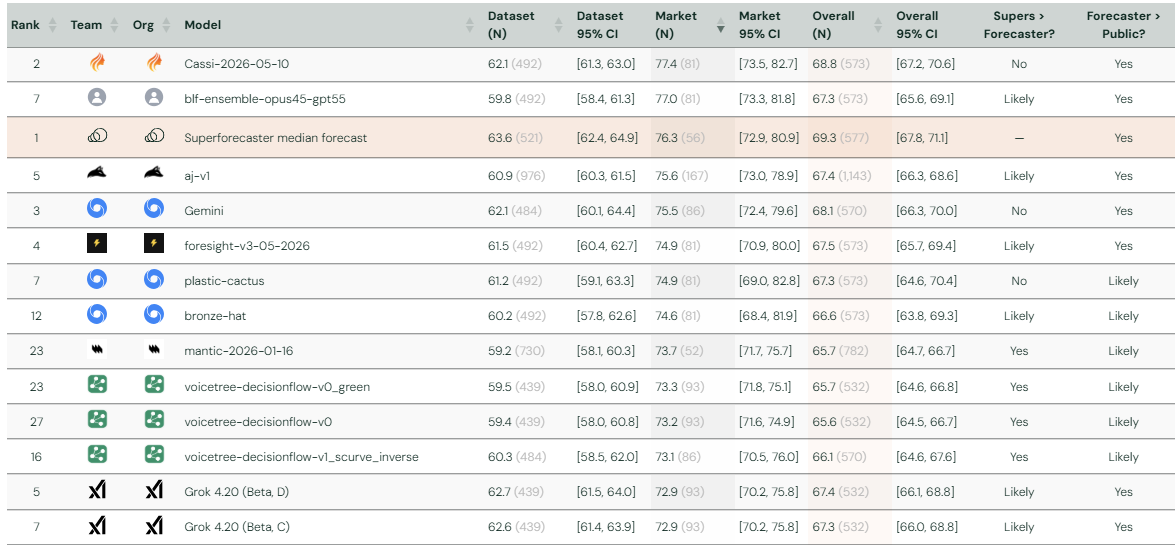
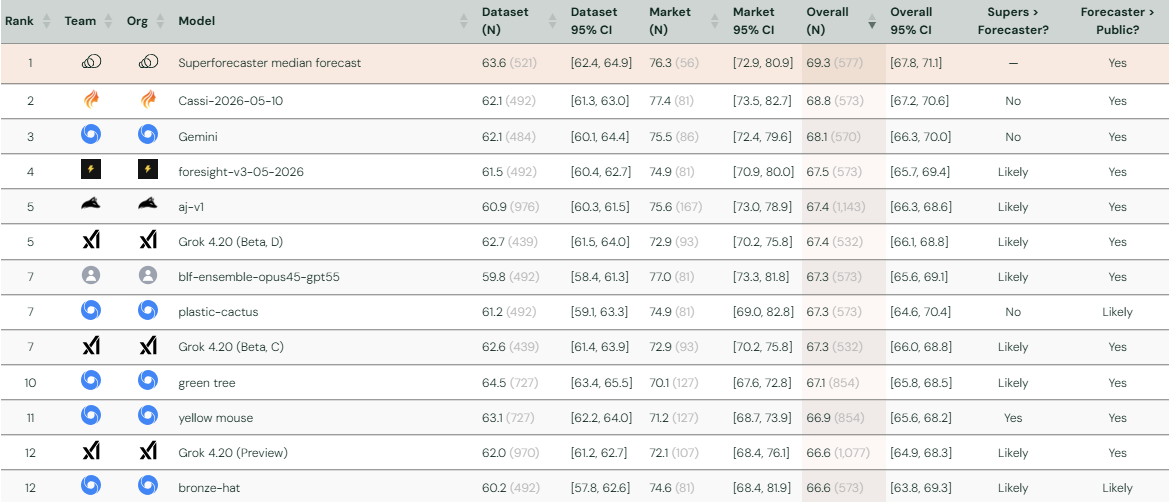
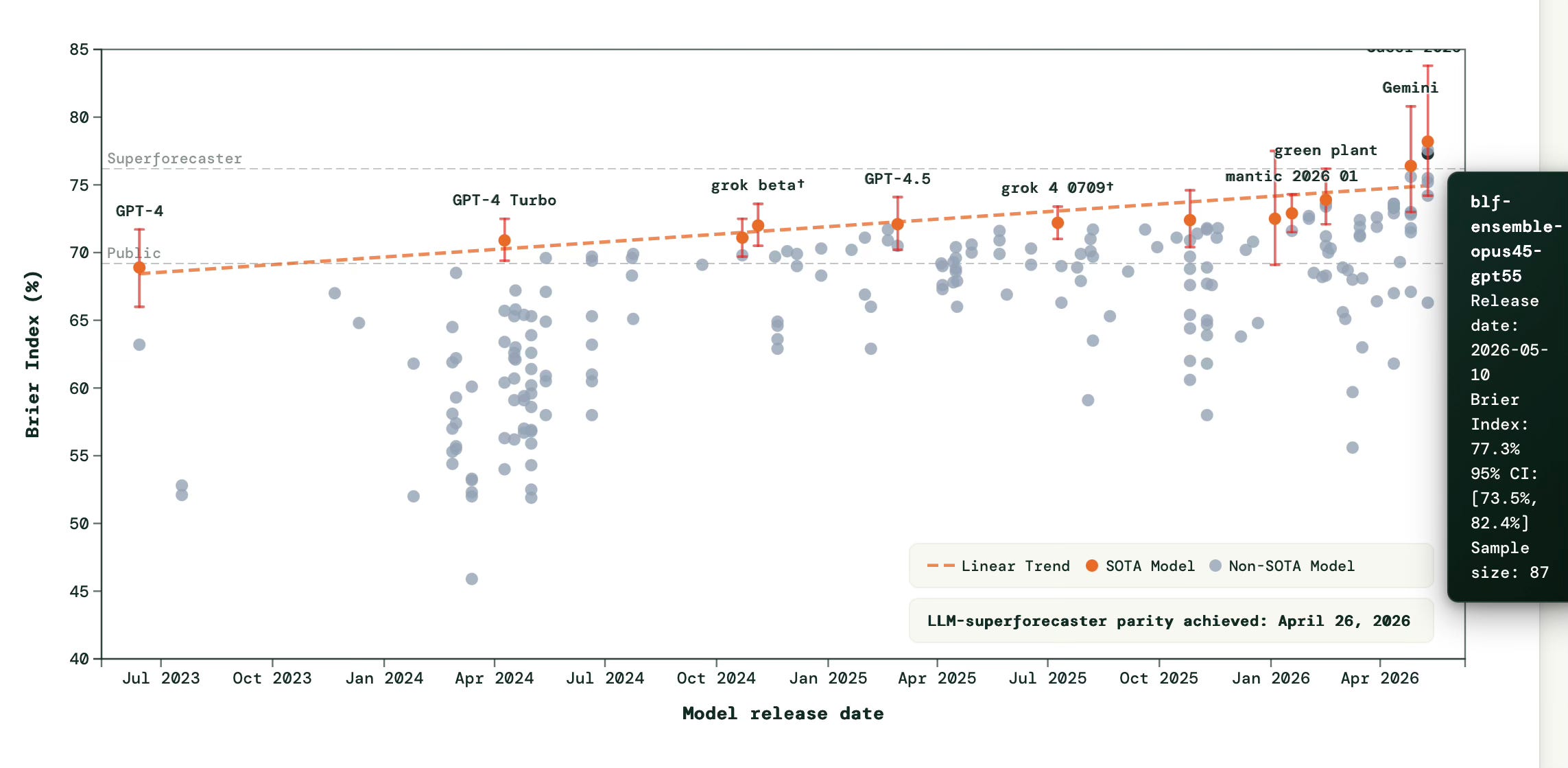
On the market-question half of ForecastBench, Anthral Labs is one of the first teams to have matched the performance of professional superforecasters. Our ensemble holds a top-3 Brier Index on market questions (as of early July 2026), statistically at par with the superforecaster median and with Cassi’s leading entry. It took under a month of exploration and under $200 in API credits - about $0.14 per question.
ForecastBench is a dynamic, contamination-free benchmark of LLM forecasting accuracy with human comparison groups, serving as a valuable proxy for general intelligence.
For context: market questions are binary questions taken from platforms like Polymarket, Metaculus, and the Rand Forecasting Initiative. Example: “Will Bitcoin trade above $84,000 in May 2026?” - priced by the market at, say, 58%. Each of these questions come with a market price which is the crowd/expert estimate of that outcome.

Dataset questions are auto-generated from public data - economic indicators, stock prices, conflict events and do not have market prices attached to them. Example: Will US unemployment be higher in the June 2026 jobs report than in May?. This requires LLMs to derive base rates from research and training data rather than use a 10 day old market price as a base rate.
Pushing the frontier on ForecastBench
Google DeepMind’s ‘green tree’ is the only model that beats the superforecaster median on dataset questions (Brier Index 64.5 vs 63.6) — but it underperforms on market questions, scoring 70.1 against the superforecasters’ 76.3.


Market-question parity with superforecasters arrived in April 2026 with Cassi’s entry, which has been competing since 2025 and has the tightest evidence behind its score. We reached the same level in our very first entry - ahead of Google DeepMind and Grok. Our ensemble (Brier Index 77.0) matches the superforecaster median (76.3), with one honest caveat: we need more questions to resolve before the confidence intervals tighten enough to confirm this holds, rather than being a good run on a small sample.
For this dataset, market prices are already a near-efficient forecast of the future. On market questions, naively copying the market’s own price gets you most of the way to the best achievable score: copying the ten-day-old price handed out with the questions scores a raw Brier of 0.156, copying the live price on forecast day scores 0.137, and our entire ensemble scores 0.142. Doing better means beating a near-optimal crowd.
Superforecasters mostly agreed with the consensus. On more than half the questions, their answer was within 5 percentage points of the market’s i.e. when they didn’t have special insight, they just went with the crowd.
The difference between human and LLM forecasters shows up entirely in the rare moments of disagreement. On the 13 questions where superforecasters strayed far from the market price, they were on the right side of it 12 times — roughly twice as accurate as the price itself on those questions.
When LLMs stray far from the market price, its prediction lands farther from reality than the price it abandoned. On average our large deviations from the live price score worse than the price itself (0.225 vs 0.212), and these moves correlate poorly with movement towards the correct predictions. e.g. Handed a ten-day-old 58% on “Bitcoin above $84K in May,” our models settled on 62%; the live market had moved to 11%.
What did we do differently in our experiment?
Forecasting requires a search+reason+search loop - “reasoning what to search, and reasoning about searched evidence”. In order to get diverse signals from an ensemble of models for forecasting, each model should be allowed to engage in its own search loops to collect different sources of articles to reason over (and do this iteratively)
What do existing setups lack?
Existing setups provide the same set of articles to all models. The BLF paper provided identical prompts, tools, and search results while swapping the base model - it found that an ensemble of models hurt, because the members produced near-identical forecasts (weaker models with little diversity hurts forecasting performance).
Cassi’s recent submissions also seem to isolate retrieval and reasoning. They have a robust retrieval pipeline, but the same evidence is provided to a panel of models for reasoning, all belonging to the same family. In the end, the LLM is given the market price with a chance to change its prediction basis the price if there is a significant deviation.
xAI gave the base model the question + standard Grok tools (X search, web search, Python REPL) to generate eight forecasts and average them.
What did we change in our harness?
We use two frontier models i.e. for each question, Claude Opus 4.5 and GPT-5.5 run independent agentic loops in parallel: it begins with a seed web search, then issues its own queries over up to five rounds of search-and-reason (via Serper) with a per-question cache that de-duplicates searches across the two models. 1
On 99% of questions the two models issued completely disjoint search queries i.e. none of the 978 questions share the same query i.e. exact same search string. Opus 4.5 issues 4 searches/question and GPT 5.5 averages 5.4.
However, since they had access to Serper it is possible that they retrieved and used the same articles/sources despite different search queries. But the reasoning traces point the other way: beyond the shared price anchor, only about one figure in ten that they quote appears in both models’ reasoning.
Both models converge to within 6 probability points on an average, however the ensemble never significantly beats its best member. GPT-5.5 alone scores a raw Brier of 0.139 on market questions where the ensemble scores 0.142. The difference (0.004) is small enough that on a fresh set of questions the ensemble would come out ahead about a third of the time (p = 0.32). It’s a tie that would cost at most a position or two on the leaderboard.
Why is this setup non-trivially useful?
The non trivial conclusion from this pipeline is that we never had to know in advance which model would be stronger. It is hard to reliably determine this in forecasting: zero-shot rankings even point the wrong way (zero-shot Opus beats zero-shot GPT-5.5 on dataset questions, yet inside our harness GPT-5.5 won both halves). Our own traces show the mechanism at its extreme.
On “Will Bitcoin reach $90K in May 2026?” (it didn’t), Opus somehow convinced itself of 97% while GPT-5.5 said 6%. The average, 59%, was still wrong but it converted a catastrophic miss into a mediocre one, cutting the penalty by more than half.
On “Will a full-scale US/Israel–Iran conflict resume by May 31?” (it didn’t), Opus said 62%, GPT-5.5 said 24%, and the average of 42% again landed meaningfully closer to reality than the worse view.
When the two models agree, it changes nothing - when they diverge, the scores aren’t as low as the base LLMs alone. The harness is able to hedge effectively and get a higher score on the leaderboard2
How to select models for the ensemble?
We can score how similar two models’ mistakes are: line up their errors across all questions and correlate them - 1.0 means they’re always wrong together, 0 means their errors are unrelated. Our two legs come out at 0.96.
How did we outperform DeepMind and xAI’s experimental models? The price each model was handed was ten days old, and in those ten days the market actually moved on half our questions (68 of 139, by 9 points on average). Each model independently tracked that movement through its own searches: Opus moved off the stale price in the right direction 75% of the time, GPT-5.5 72%, each capturing roughly 40% of the true movement (slope 0.40). That reconstruction is worth most of our score: copying the stale price scores 0.156, our ensemble 0.142, the true current price 0.137.
What do most bots do? Models without search either echo the stale price verbatim or guess around it - they forecast as if the news stopped when the snapshot was taken. Every serious team can reconstruct nearly 90% of the movement from the 10 day price to the live forecast. We reconstruct about half - ‘brass-apple’ and FutureSearch’s submissions on the preliminary leaderboard are likely to outperform our ensemble after the 50 day cooldown period.
What next?
While these early experiments are promising, we want to scale the # of questions our models forecast and build better harnesses that allow frontier models (closed and OSS) to forecast economically valuable markets with more nuance. Over time, we push SOTA on sample efficient, continual learning to build self improving agents that trade financial markets.
We will start with prediction markets related to the US midterm elections in Nov 2026.
Notes on future work
Superforecaster predictions were made in 2024 and are expected to be updated with a new survey in Fall 2026. In the meanwhile, 20/78 Qs answered by these superforecasters are scored periodically (every 2 weeks) against the live probability of these questions from the relevant prediction market source. Technically, we are testing a stale prediction made 2 years ago with the market price as your ceiling for supers vs predictions with more information and shorter timelines for LLMs in the normal forecastbench leaderboard. While parity with superforecasters is an interesting sign of how harnesses can compound base model capabilities, it should be interpreted with a pinch of salt due to the nature of comparison. While answering more questions (greater n) tightens confidence intervals, comparing with human superforecasters is messy and moot - the real comparison is the ability of LLMs to beat market prices. Currently public LLMs with simple harnesses have not been able to do this. However, scaling RL in financial markets will allow us to learn continuously across a large range of markets which human traders, desks and entire funds struggle to do.
The setup does not provide LMs with all necessary tools for clean forecasts. ForecastBench autogenerates several numerical questions which often lack clean data from web searches leading models to default to a coin flip prediction. (e.g. BTC price, weather - they lack statistical tools and access to datasets needed to make these predictions) This is at best an evaluation of whether models know when to not answer a question vs make a prediction with high conviction - which is a measure of calibration and not forecasting. Hence, the setup and questions we use to evaluate LMs on long horizon forecasting need to look vastly different (closer to FutureSim).
Frontier models think in similar ways - they lack taste necessary for identifying contrary insights, which is the core capability that allows you to outperform liquid markets. We want to run experiments similar to what Bridgewater AIA Labs released in collaboration with Tinker where they trained a 200B+ param model to classify relevant documents/articles to generate investment thesis.
If you are working on prediction markets, forecasting or applying RL/machine intelligence to autonomously trade financial markets reach out to us at harsith@anthral.com or rajat@anthral.com
GPT 5.5 reports a summary of the reasoning (550 chars per question) compared to the detailed scratchpad traces we have from Opus 4.5 (4000 chars per question). Even after accounting for GPT-5.5’s brevity, the evidence bases differ: on the typical question, more than half of the figures GPT cites appear nowhere in Opus’s far longer scratchpad, and GPT’s citations are fully contained in Opus’s on only 6% of questions. This implies that they share the same anchors but reason over different facts
We are working on improving forecasting benchmarks to be more reliable and less sensitive to benchmark maxxing